Un cofundador de la 'joya' francesa de IA pirateó millones de libros cuando trabajaba en Meta
La piratería es un robo salvo, quizás, cuando se trata de una empresa de inteligencia artificial (IA). En Estados Unidos hay abiertos más de setenta procedimientos que enfrentan a artistas, escritores, actores o editoriales con los gigantes que fabrican los “grandes modelos de lenguaje” (large language model, LLM), motores de la IA generativa (la que produce textos e imágenes).
Esos creadores acusan a OpenAI, Anthropic o Meta, la empresa matriz de Facebook, de saquear sus obras para entrenar sus herramientas, en contravención de las normas de derechos de autor.
Uno de esos procedimientos es el caso “Kadrey contra Meta Platforms Inc.”, iniciado en 2023 y llevado a cabo por escritores como Richard Kadrey, Sarah Silverman o Ta-Nehisi Coates. Lo que está en juego es enorme: validar el modelo económico de los pioneros de la IA o abrir la vía a una remuneración masiva a los autores cuyos contenidos han sido utilizados sin su consentimiento y sin contraprestación alguna.
El análisis realizado por Mediapart de los miles de páginas de documentos hechos públicos con este motivo, enriquecido con entrevistas a exempleados de Meta, es muy revelador. Permite confirmar, como reveló en marzo en Estados Unidos la revista The Atlantic, que Meta ha entrenado su modelo de inteligencia artificial generativa, LLaMA, basándose en millones de libros acumulados por Library Genesis (LibGen), una web pirata que también recopila millones de artículos científicos.
Mediapart revela que estos documentos también demuestran la importante implicación, en 2022, de Guillaume Lample, que entonces era empleado de Meta. Luego fundaría Mistral AI, la joya francesa de la inteligencia artificial, empresa favorita de Macron valorada en 12.000 millones de euros, de la que Lample es director científico. Los documentos públicos demuestran que el investigador y empresario está detrás del pirateo de varias decenas de terabytes (es decir, miles de gigabytes) de datos.
Como muestran varias comunicaciones internas, la empresa de Mark Zuckerberg consideraba, a finales de 2023, que Mistral AI también había utilizado LibGen. Al ser preguntado sobre estos dos puntos, Guillaume Lample no respondió, a pesar de nuestros insistentes intentos. Meta tampoco respondió a nuestras preguntas.
Otoño de 2022: hay urgencia en Meta
En 2022, Mistral AI no existe. Guillaume Lample, ingeniero por la Universidad Politécnica, llegó a Meta en 2014 y ya era conocido por sus trabajos pioneros en el campo de la traducción automática. En aquel momento trabajaba en el laboratorio Fundamental AI Research (Fair). La estructura, creada en 2015, está dirigida por el francés Yann Le Cun, una auténtica estrella del sector, y cuenta con un importante equipo en París. “Los equipos de Fair funcionaban como un centro de investigación, recuerda un antiguo empleado de Meta. Trabajaban con gran autonomía con respecto a los objetivos comerciales de la empresa”.
Pero el ambiente cambia en otoño de 2022. Unos meses antes, Midjourney había lanzado un software de generación de imágenes y OpenAI se dispone a hacer público ChatGPT. Los ingenieros de Meta son muy conscientes de su retraso. Dos equipos de Fair, en Estados Unidos y Francia, trabajan en paralelo en la creación de un LLM. Buscan, con urgencia, adquirir datos.
El reto es cuantitativo: entrenar un LLM supone tragarse miles de millones de páginas de texto. Pero también es cualitativo. Dado que la IA imita lo que consume, los ingenieros deben alimentarla con textos bien escritos y bien estructurados. Por lo tanto, los libros, pero también los artículos científicos, aparecen como las fuentes particularmente interesantes para los equipos de Meta.
Antes de realizar ninguna compra, deciden poner a prueba esta teoría. Rápidamente se plantea la cuestión de utilizar LibGen. Este proyecto colaborativo, creado a mediados de la década de 2010 y alimentado por la cultura pirata de la época, tiene como objetivo hacer gratuitos los artículos de investigación y las obras protegidas por derechos de autor. En su apogeo, la web aglutina más de 6 millones de obras y al menos 80 millones de artículos científicos.
No creo que debamos utilizar obras pirateadas. Es una línea roja
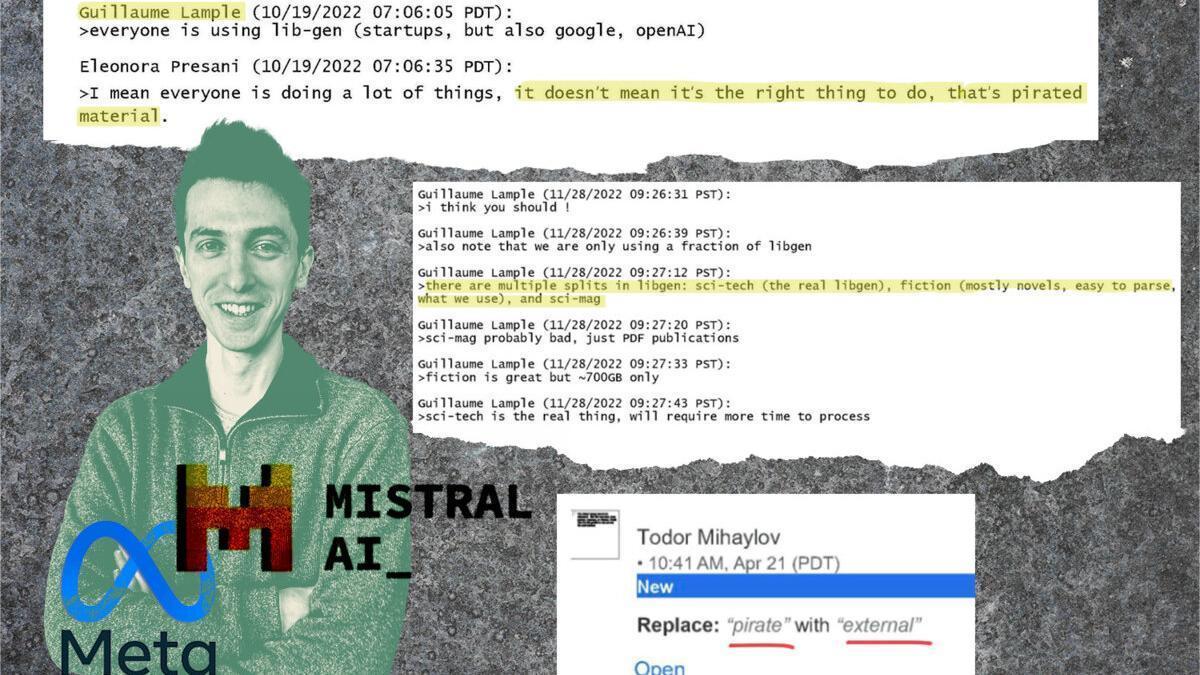
A partir de octubre, los equipos de Fair se plantean el uso de estos datos. Al menos quieren realizar pruebas. El 7 de octubre de 2022, tal y como indica un email interno, los responsables del laboratorio se organizan para obtener la autorización para utilizar LibGen. El 19 de octubre, un largo intercambio de emails detalla los retos para los equipos de investigación de Meta. “Los mejores recursos son, sin duda, los libros”, detalla un investigador de la empresa, que considera que, antes de comprar estas obras, hay que “empezar por hacer una prueba con y sin libros para demostrar el valor de las obras”.
“Guillaume y el equipo de París esperan los datos para demostrarlo”, dice. Para este investigador, es necesario “ponerse en contacto con los editores más importantes” o “comprar libros en masa por Internet”. No hay consenso sobre el tema. “No creo que debamos utilizar obras pirateadas. Es una línea roja”, protesta una investigadora, que se niega a utilizar “webs de piratería ilegales”.
“Todo el mundo utiliza LibGen”, argumenta entonces Guillaume Lample. Una postura reiterada a finales de noviembre de 2022, en otro intercambio de emails en el que una miembro de Fair vuelve a mostrar su preocupación por el uso de LibGen. “Eso es lo que hace OpenAI con GPT3, lo que hace Google con [el LLM] Palm, lo que hace DeepMind con Chinchilla”, replica Guillaume Lample. “Así que nosotros también lo vamos a hacer.”
El uso exploratorio queda validado y Lample comienza a piratear los contenidos recopilados en la plataforma, como lo demuestran los códigos revelados en el marco de la investigación, los emails internos y varias declaraciones. Estas descargas, iniciadas en octubre de 2022, duran varios meses y se refieren principalmente a la parte científica de LibGen.
Descargas P2P
Para ello, el ingeniero utiliza un protocolo Torrent, una tecnología peer-to-peer (P2P) que permite descargar un archivo de decenas, cientos o miles de otros usuarios que ya lo poseen en su totalidad o en parte. Este uso también implica poner a disposición de los internautas los archivos descargados, lo que facilita futuras piraterías. Los demandantes del caso “Kadrey contra Meta Platforms Inc.” estiman en muchos documentos que el francés descargó unos 70 TB de datos en total.
Ni Meta ni Guillaume Lample han respondido a nuestras preguntas, pero los registros de descargas de este último, que recogen su actividad informática mientras trabajaba para Meta, confirman su total implicación. Su análisis solo ha podido abarcar una fracción de las descargas: “Los registros [proporcionados por Meta, ndr] están incompletos”, señala el experto encargado del análisis. De los más de 70 TB de datos que Lample habría descargado a través de Torrent, los registros solo cubren 3,9 TB”. El informe también señala “datos que incluyen documentos procedentes de LibGen”.
En aquella época, Lample y sus colegas trabajaban sin descanso para finalizar lo antes posible un modelo de LLM comercializable. El 27 de febrero de 2023, Meta hace público LLaMA 1. La empresa ha decidido dejar a un lado los datos obtenidos en LibGen y utilizar datos de entrenamiento compatibles con la publicación del modelo en código abierto.
A partir del 28 de febrero de 2023, Guillaume Lample y sus colegas se plantean cómo obtener aún más datos
LLaMA 1 se basa, no obstante, en datos protegidos. El artículo que explica el funcionamiento del modelo, firmado conjuntamente por Guillaume Lample y Timothée Lacroix, también cofundador de Mistral AI, menciona el uso de “Books3”, una base de datos que contiene obras protegidas por derechos de autor, para su entrenamiento.
Al día siguiente, 28 de febrero, se reanuda la carrera por la innovación. Guillaume Lample y sus colegas se plantean cómo obtener aún más datos. En las semanas siguientes, los equipos de ingenieros de Meta presionan a la dirección para que adquiera “el máximo de textos de formato largo”.
Como revelaron varias declaraciones dentro del procedimiento judicial en Estados Unidos, Meta considera inicialmente pagar por el acceso a las obras e incluso habla de un presupuesto de 200 millones de dólares. Pero esa opción acaba descartándose. A principios de abril de 2023, circula por la empresa un memorándum interno en el que se detallan las fuentes de datos disponibles gratuitamente o fácilmente pirateables.
El 7 de abril, Meta emite una directiva dirigida a sus equipos: deben suspender la negociación de licencias. Los ingenieros vuelven a recurrir a datos pirateados. En mayo de 2023, se vuelven a descargar millones de libros y artículos accesibles en LibGen.
Piratería en secreto
El origen de los documentos se va ocultando poco a poco. Los ingenieros dejan de hacer referencia a los datos pirateados, que se convierten en documentos “externos”. El 19 de diciembre de 2023, siguiendo el consejo del equipo de investigación, Meta decide utilizar los datos recopilados en LibGen para entrenar la tercera versión de LLaMA, sin revelar el uso de estas bases de datos.
Al año siguiente, basándose una vez más en un protocolo Torrent, los equipos de Meta recuperan los documentos recopilados en “Anna's Archive”, una base de datos pirateada aún más importante que LibGen, que se utilizará para entrenar las versiones más recientes de LLaMA.
Guillaume Lample en ese momento ya no está allí. Poco después de finalizar LLaMA 1 en la primavera de 2023, parece que se distanció de Meta. Otro ingeniero se encargó de coordinar la adquisición de datos. “Varias personas del equipo francés se tomaban muchas vacaciones, da la impresión de que empezaban a bajar el ritmo”, explica una fuente que ha analizado el importante expediente judicial estadounidense. “El equipo francés llevaba varios meses preparando una recaudación de fondos para [su] propio proyecto”, detalla un exempleado de Fair. “Utilizaron LLaMA 1 como trampolín”.
Los documentos del procedimiento también destacan las dificultades de Fair justo después de la publicación de LLaMA 1. Los datos recopilados por Lample y su equipo ya no son accesibles para una parte de Meta. “Se bloqueó el acceso a los datos y a las pruebas de evaluación para que nadie pudiera reconstruir completamente el proceso de entrenamiento de LLaMA 1”, confirma a Mediapart un exempleado.
Septiembre de 2023, Mistral AI publica su modelo
En abril de 2023, un nuevo equipo se encarga de adquirir datos y descarga una nueva versión de LibGen. Entretanto, Lample y los demás cofundadores de Mistral buscan inversores. Entre sus promesas figura el uso de datos de “alta calidad”, para los que la joven empresa se compromete a negociar acuerdos de licencia.
En septiembre de 2023, Mistral lanza su propio modelo, Mistral 7B, con un rendimiento comparable al de sus competidores americanos. Este primer éxito sigue siendo la piedra angular de los productos actuales de la empresa.
¿De dónde proceden los datos utilizados para entrenarlo? “Mistral AI no es transparente en lo que respecta a los datos de entrenamiento”, señala Margarida Silva, investigadora del Centro de Investigación sobre Corporaciones Multinacionales (Somo). “Mistral no comparte ni los datos que utiliza ni los algoritmos empleados para desarrollar los modelos”, coincide Harshvardhan Pandit, investigador del AI Accountability Lab del Trinity College de Dublín (Irlanda).
Uno de los máximos responsables de Meta escribe que el equipo de investigación sabe, por el boca a boca, que OpenAI y Mistral utilizan LibGen para sus modelos
La empresa asegura a Mediapart que los datos utilizados contienen “información pública disponible en Internet, conjuntos de datos no públicos con licencia de terceros, así como datos generados internamente de forma sintética”. A principios de 2025, la empresa firmó un acuerdo de asociación con la AFP. Desde 2024, también participa en el proyecto ArGiMi, que le permite acceder a parte de las colecciones del Instituto Nacional de lo Audiovisual y de la Biblioteca Nacional de Francia. Estas colaboraciones comenzaron mucho después del lanzamiento de Mistral 7B.
En Meta, los investigadores del Fair tienen otra idea sobre el origen de los datos de Mistral AI. En un email del 19 de diciembre de 2023 que valida el uso de LibGen por parte de Meta para entrenar su tercera versión de LLaMA, uno de los máximos responsables de la empresa escribe que el equipo de investigación “sabe, por el boca a boca, que OpenAI y Mistral utilizan LibGen para sus modelos”. El argumento va acompañado de una tabla que compara el rendimiento de las diferentes herramientas y atribuye la eficacia del software de Mistral al uso de datos pirateados.
“LLaMa y Mistral 7B son muy parecidos”, explica a Mediapart un exempleado de Meta. “No tengo ninguna duda de que Mistral ha utilizado LibGen”. Un análisis ampliamente compartido por varios especialistas consultados. “Es un tema complicado. Entiendo por qué las empresas de IA lo hacen sin decírselo al público y por qué eso enfada a la gente”, precisa un destacado investigador.
El reglamento europeo sobre inteligencia artificial, aprobado en el verano de 2024, establece que las empresas de IA generativa deben comunicar un resumen de los datos de entrenamiento utilizados en sus modelos. Un documento que Mistral AI aún no ha publicado.
Caja negra
El 11 de diciembre de 2025, Mediapart envió una serie de preguntas a numerosos interlocutores, entre ellos Mistral AI, Meta y Guillaume Lample. A pesar de nuestros diferentes intentos, a través de las redes sociales, por teléfono y a través del servicio de prensa de Mistral AI, Guillaume Lample no respondió. Meta tampoco.
La coautora de este artículo, Soizic Pénicaud, investiga los efectos de la tecnología digital y la inteligencia artificial. Colabora habitualmente con el colectivo de periodistas Lighthouse Reports. También es cofundadora de l'Observatoire des algorithmes publics y profesora en la facultad de Ciencias Políticas de Paris.
Esta investigación se ha llevado a cabo con el apoyo del Tarbell Center.

Bruselas quiere retrasar algunas partes de su ley de inteligencia artificial
Ver más
Traducción de Miguel López




